Các khái niệm cốt lõi của LLM và AI Model hiện đại

Nếu bạn từng nghe về ChatGPT, Gemini, Claude hay bất kỳ mô hình AI hiện đại nào, chắc hẳn đã không ít lần bắt gặp những thuật ngữ như temperature, tokens, parameters 7B/13B/70B, shots, benchmarks như GSM8K, MMLU, hay thậm chí là Chain of Thought (CoT). Chúng xuất hiện dày đặc trong các bài viết, tweet công nghệ, tài liệu kỹ thuật… và đôi khi, với người mới tìm hiểu, tất cả nghe chẳng khác gì “ngôn ngữ của người ngoài hành tinh”.
Vậy thực chất, những khái niệm này nói lên điều gì về cách AI hoạt động? Chúng có ý nghĩa gì trong việc tạo ra một chatbot thông minh hay một AI giải toán, viết code, soạn nhạc? Và tại sao ai cũng nhắc đến context size hoặc autoregressive khi nói về các mô hình ngôn ngữ lớn (LLM)?
Trong bài viết này, chúng ta sẽ cùng “giải mã” những thuật ngữ cốt lõi làm nên sức mạnh của các mô hình AI hiện đại – theo cách đơn giản, đời thường nhất. Dù bạn là người mới tò mò, dân công nghệ muốn cập nhật, hay chỉ muốn hiểu vì sao AI lại đang làm mưa làm gió, đây sẽ là chiếc bản đồ giúp bạn bước vào thế giới AI một cách tự tin, không lo lạc lối.
1 Giới thiệu
Grok 1, mô hình LLM mã nguồn mở của xAI, vừa được công bố open source vào tháng 3 năm 2024. Trang web của xAI mô tả về Grok 1 như sau.
Grok-1 là một mô hình Mixture-of-Experts với 314 tỷ tham số được huấn luyện từ đầu bởi xAI. Sau khi công bố xAI, chúng tôi huấn luyện một nguyên mẫu LLM (Grok-0) với 33 tỷ tham số. Mô hình thử nghiệm này đạt gần năng lực của LLaMA 2 (70B) trên các benchmark tiêu chuẩn nhưng chỉ sử dụng một nửa tài nguyên huấn luyện. Grok 1 là một autoregressive LLM vừa được phát hành và có các chỉ số benchmark với 30B được đánh giá ở temperature 0.1 với context window 1092 token. Bản Grok-1 đầu tiên có context length là 8,192 token và được phát hành vào tháng 11 năm 2023. Tham khảo: https://x.ai/blog/grok/model-card
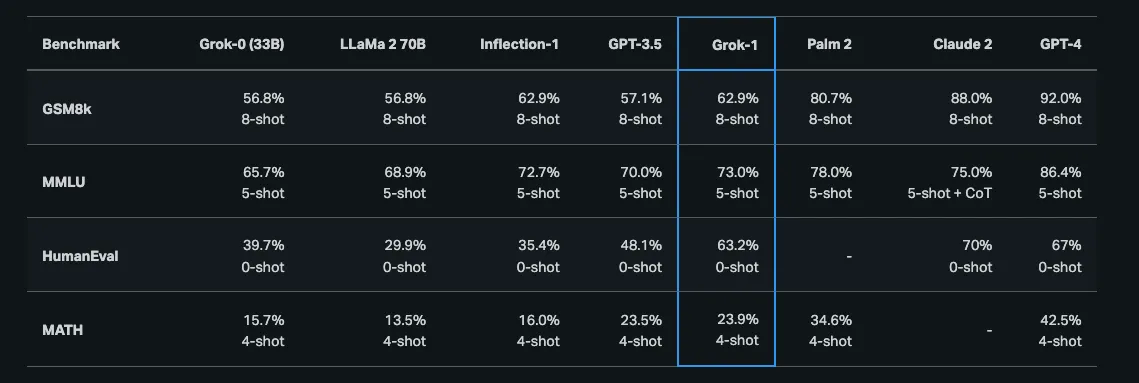
Ngoài ra khi đọc về các mô hình AI bạn sẽ thường gặp các mô tả như sau:
Sau đây là các thông số nhanh về Llama 2, mô hình AI của Meta AI. Params: 7B đến 70B tham số (7B, 13B, 70B) Context size: 4048 Trained on: 2 nghìn tỷ token Github: Source Code Try it: HuggingFace
Vậy thực sự những khái niệm như temperature, shots, parameters ví dụ 7B, 13B, 70B, và Benchmarks (GSM8K, MMLU), CoT, Autoregressive LLMs là gì?
2 Parameters(Tham số) (70B vs 7B parameters(Tham số)) — Kích thước và Độ phức tạp của mô hình AI
70B nghĩa là mô hình đó có 70 tỷ tham số. Đây là một thước đo về kích thước và độ phức tạp của mô hình AI. Thông thường, số lượng tham số càng lớn thì mô hình càng phức tạp và mạnh mẽ.
Grok-1 là một mô hình với 314 tỷ tham số, lớn hơn và phức tạp hơn.
Trong bối cảnh các mô hình machine learning, đặc biệt là neural network, tham số là các giá trị số mà mô hình học được và điều chỉnh trong quá trình huấn luyện.
Số lượng tham số lớn hơn thường cho phép mô hình biểu diễn được các mối quan hệ phức tạp hơn trong dữ liệu và có thể đạt hiệu năng tốt hơn trên các tác vụ.
Các mô hình AI có nhiều kích thước và mức độ phức tạp khác nhau. Tuy nhiên, điều quan trọng là số lượng tham số không phải yếu tố duy nhất quyết định hiệu quả của một LLM. Các yếu tố khác như kiến trúc mô hình, dữ liệu huấn luyện và kỹ thuật huấn luyện cũng đóng vai trò quan trọng.
Ngoài ra, 70B dùng để chỉ số lượng tham số trong mô hình, không phải kích thước dữ liệu huấn luyện.
Ví dụ, một mô hình LLM 70B có thể được huấn luyện trên petabytes dữ liệu.
Lưu ý rằng cả số lượng tham số và kích thước dữ liệu huấn luyện đều là những yếu tố then chốt ảnh hưởng đến hiệu năng của các mô hình ngôn ngữ lớn.
Tuy nhiên, không phải lúc nào cũng cần dùng mô hình lớn, và xu hướng hiện tại là phát triển các mô hình AI nhỏ hơn về số lượng tham số như 7B, sử dụng ít tài nguyên huấn luyện hơn.
Ví dụ, bản phát hành Llama 2 giới thiệu một họ các LLM được huấn luyện sẵn và tinh chỉnh, có quy mô từ 7B đến 70B tham số (7B, 13B, 70B).
Các mô hình AI lớn đòi hỏi nhiều tài nguyên tính toán để chạy và thường phải vận hành trên các máy chủ lớn chuyên dụng.
Vì vậy, các mô hình AI nhỏ hơn nhưng vẫn đạt chất lượng tương đương mô hình lớn có thể được ưu tiên nếu muốn chạy trên laptop hoặc smartphone.
Điều này có thể đạt được nhờ quá trình AI Model distillation, nơi một mô hình nhỏ hơn có thể học cách bắt chước quyết định của một mô hình lớn hơn, phức tạp hơn.
3 AI Model distillation
Model distillation là một quy trình machine learning dạy cho một mô hình nhỏ, đơn giản (“student”) bắt chước một mô hình lớn, phức tạp (“teacher”).
Bằng cách học từ output của teacher, student model có thể đưa ra các quyết định tương tự mà không cần phải là một mô hình lớn, phức tạp. Những student AI model này có thể nhỏ hơn về kích thước, nhanh hơn và tiết kiệm tài nguyên tính toán, có thể chạy trên điện thoại hoặc laptop.
Ví dụ: (SQLCoder 7B vs SQLCoder70B) là một mô hình AI mã nguồn mở mà một số người cho rằng vượt trội hơn GPT 4, được Defog phát triển trên nền codeLlama-70B.
3.1 Quy trình Distillation:
- Pre-trained Teacher Model: Quá trình bắt đầu với một mô hình lớn, đã được huấn luyện sẵn trên tập dữ liệu lớn và thực hiện tốt một nhiệm vụ cụ thể (ví dụ: phân loại ảnh, dịch ngôn ngữ).
- Knowledge Transfer: Trong quá trình distillation, teacher model đóng vai trò hướng dẫn, truyền đạt kiến thức một cách gián tiếp cho student model.
- Student Model Training: Student model được huấn luyện dựa trên hai nguồn thông tin:
- Dữ liệu huấn luyện gốc dùng cho teacher model.
- Các dự đoán (output) của teacher model trên cùng dữ liệu đó. Điều này về cơ bản giúp student model học cách bắt chước hành vi của teacher model.
4. Student nhỏ gọn, hiệu quả: Qua quá trình huấn luyện này, student model học được cách thực hiện tương tự teacher model, nhưng với kích thước nhỏ hơn và yêu cầu tính toán thấp hơn đáng kể.
4 HuggingFace và OpenSource AI
Các mô hình AI có thể là proprietary (đóng mã nguồn) ví dụ như ChatGPT (OpenAI), Gemini (Google AI), Claude (Anthropic AI), v.v. hoặc open source như Llama 2 (Meta AI), Grok 1 (x AI), v.v.
Các mô hình AI mã nguồn mở cho phép bạn xem mã nguồn và phát triển thêm dựa trên đó.
Có rất nhiều mô hình AI mã nguồn mở có sẵn trên HuggingFace (Github của AI Models). https://huggingface.co/models
Tính đến tháng 3 năm 2024, HuggingFace có hơn 500.000 mô hình AI mã nguồn mở.
Nếu mô hình AI là open source thì người dùng có thể triển khai, chạy và xây dựng thêm trên đó.
Các mô hình AI nhỏ open source có thể triển khai trên laptop mạnh, các mô hình lớn hơn có thể chạy trên cloud. Google Vertex AI là nền tảng cloud của Google để chạy các mô hình AI.
5 Xây dựng, chạy và triển khai AI Models của riêng bạn
Google Vertex AI cung cấp nền tảng cloud nơi bạn có thể triển khai và chạy các AI Model từ HuggingFace.
Vertex AI là nền tảng machine learning (ML) cho phép bạn huấn luyện và triển khai các mô hình ML, ứng dụng AI, và tuỳ chỉnh các large language model (LLMs) cho ứng dụng AI của bạn. Vertex AI cung cấp một nền tảng thống nhất tích hợp liền mạch các khâu chuẩn bị dữ liệu, huấn luyện mô hình, triển khai và giám sát. Điều này giúp giảm đáng kể độ phức tạp trong quản lý các thành phần riêng lẻ.
Tham khảo:
- https://huggingface.co/blog/gcp-partnership
- Deploying 🤗 Hub models in Vertex AI https://huggingface.co/blog/alvarobartt/deploy-from-hub-to-vertex-ai
- Vertex AI pricing https://cloud.google.com/vertex-ai/generative-ai/pricing
6 Tokens
Tokens là cách biểu diễn các từ trong một mô hình AI và là đơn vị thông tin cơ bản được sử dụng để biểu diễn dữ liệu văn bản.
Trong các LLM về NLP, từ ngữ được truyền vào AI Model dưới dạng token. Các từ được chuyển đổi thành token, sử dụng một phương pháp tokenization nhất định.
Quá trình chuyển đổi văn bản thành token được gọi là tokenization. Điều này bao gồm việc chia nhỏ văn bản thành các đơn vị cấu thành dựa trên phương pháp tokenization đã chọn.
Việc lựa chọn phương pháp tokenization và kích cỡ, sự đa dạng của dữ liệu huấn luyện (được đo bằng số lượng token) ảnh hưởng lớn tới khả năng của LLM.
Ví dụ
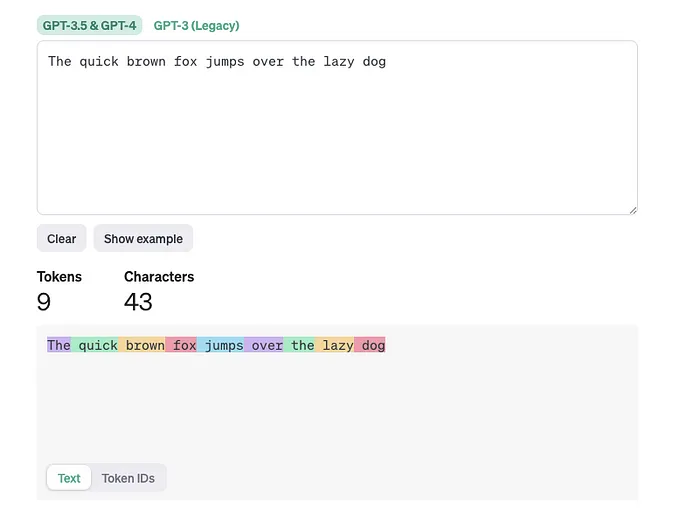
Text Tokens
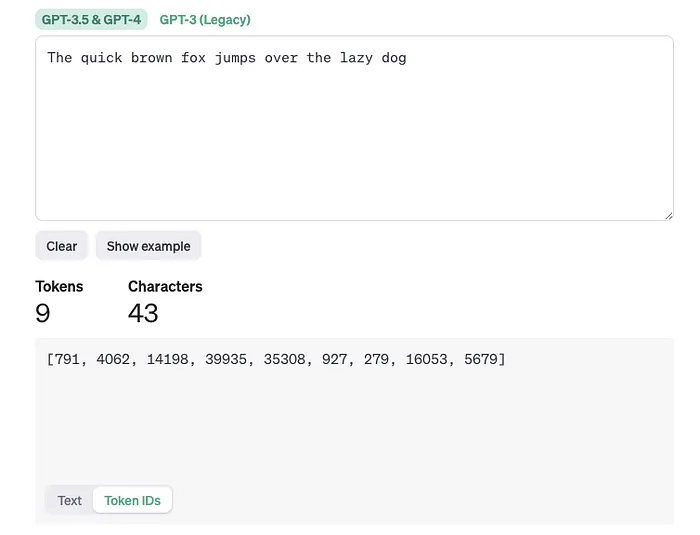
Token Ids
Tham khảo: https://platform.openai.com/tokenizer
LLM (Large Language Model) đúng như tên gọi là các mô hình AI được huấn luyện trên các bộ dữ liệu văn bản lớn.
Ví dụ, một LLM được huấn luyện trên bộ dữ liệu 2 nghìn tỷ token, tức là được huấn luyện trên một lượng dữ liệu văn bản khổng lồ, và chính điều này cho phép LLM phát triển khả năng hiểu ngôn ngữ.
Nói chung, càng được huấn luyện trên nhiều token, LLM càng được tiếp xúc với nhiều từ, cụm từ, cách dùng ngôn ngữ đa dạng. Điều này giúp cải thiện:
- Từ vựng: LLM tiếp xúc nhiều từ hơn và học được nghĩa của chúng.
- Ngữ pháp và Cú pháp: Học được các quy tắc ngữ pháp và cách xây dựng câu đúng.
- Sắc thái và Ngữ cảnh: LLM hiểu tốt hơn các sắc thái và ý nghĩa thay đổi tuỳ theo ngữ cảnh.
6.1 Tại sao lại dùng token?
Biểu diễn từ thành token cho phép các mô hình AI xử lý dữ liệu về mặt toán học, từ đó áp dụng được các kiến trúc AI khác nhau để thiết lập quan hệ toán học giữa các từ và dữ liệu, giúp AI tạo ra “context” cho dữ liệu.
Do token là đơn vị cơ bản trong input cho AI Model, nhiều AI Model sử dụng token làm đơn vị đo lường khi tính phí sử dụng input/output dữ liệu.
Tham khảo: https://openai.com/pricing

GPT 4 Turbo Pricing Model (theo lượng token sử dụng)
Bạn có thể hình dung token là các mảnh ghép của từ được dùng trong xử lý ngôn ngữ tự nhiên. Đối với tiếng Anh, 1 token tương đương khoảng 4 ký tự hoặc 0.75 từ. Ví dụ, toàn bộ tác phẩm của Shakespeare là khoảng 900.000 từ hay 1.2 triệu token.
7 Context Length vs. Context Window
7.1 Context length
Context length là số lượng token tối đa mà AI model có thể xử lý cùng lúc.
Ví dụ, với ChatGPT 3.5 là 4096 token. Nghĩa là ChatGPT 3.5 không thể nhận input dài hơn 4096 token (sẽ bị cắt bớt). Điều này cũng có nghĩa là GPT 3.5 không thể tạo ra output dài hơn 4096 token trong một lần, mà phải chia thành nhiều phần.
Ví dụ, tôi yêu cầu GPT 3.5 liệt kê các số từ 1 đến 1000, yêu cầu này sẽ vượt quá context length 4096. GPT 3.5 sẽ dừng lại khi đạt giới hạn này và yêu cầu tôi “tiếp tục”, sau đó sinh tiếp ở phần kế tiếp.
Lưu ý: bản Grok-1 đầu tiên có context length là 8,192 token và phát hành tháng 11 năm 2023.
Ngoài ra, context length còn thường được ghi ngay trong tên AI model, ví dụ “XGen-7B-4K-base” (Salesforce AI), trong đó “4K” có thể chỉ context length (số token tối đa xử lý), tức là 4096 token. Nghĩa là model này có thể xử lý tối đa 4096 token khi tạo ra phản hồi.
Lưu ý, 7B thể hiện kích thước/độ phức tạp của model, nhưng dù chỉ 7 tỷ tham số, XGen vẫn cho hiệu năng ngang hoặc hơn nhiều AI model lớn hơn.
7.2 Context Window
Context window là số token mà AI model thực sự xét khi tạo ra phản hồi. Nó thường bao gồm các token gần nhất trong hội thoại, giúp model tạo ra câu trả lời phù hợp và nhất quán theo bối cảnh cuộc trò chuyện.
Context window giúp AI model “nhớ” bạn đã nói gì về chủ đề đó ở các prompt trước. Điều này giúp tạo ra các phản hồi tự nhiên và logic.
Context window ở các language model như GPT là lượng văn bản model có thể nhớ khi tạo phản hồi.
Nó chính là “bộ nhớ làm việc” của model, quyết định lượng thông tin trước đó model có thể ghi nhớ trong cuộc trò chuyện, rất quan trọng để giữ mạch logic và độ liên quan trong hội thoại hoặc văn bản sinh ra.
Context length của GPT 3.5 là 4096 token, tức là xử lý tối đa 4096 token/lần.
Context window của GPT 3.5 là 2048 token, tức là model chỉ thực sự xét 2048 token gần nhất khi tạo ra phản hồi.
GPT-4 Turbo có context window là 128k token, tương đương hơn 300 trang văn bản. Điều này cho phép model tạo ra phản hồi giàu thông tin và ngữ cảnh hơn nhiều.
7.3 “5-shot in-context” nghĩa là gì?
“Shot” (như “5-shot in-context”) là cách cung cấp một số ví dụ liên quan (các “shot”) cho mô hình ngôn ngữ lớn (LLM) trước khi thực hiện nhiệm vụ. Điều này giúp model hiểu rõ hơn về ngữ cảnh và cách giải quyết vấn đề, từ đó tăng hiệu quả ở những câu hỏi cần suy luận tinh tế. Có thể hiểu đơn giản là cho LLM “xem trước” các ví dụ để giúp nó giải quyết tốt hơn.
5-shot in-context: Đây là một khái niệm quan trọng trong quá trình đánh giá AI Model, cụ thể:
- 5-shot: Trước khi trả lời, LLM được cung cấp 5 ví dụ hoặc đoạn trích liên quan (shot) cung cấp ngữ cảnh cho câu hỏi. Điều này giúp model hiểu rõ hơn về chủ đề, cách suy luận cho câu hỏi.
- In-context: 5 ví dụ đó liên quan trực tiếp tới câu hỏi được hỏi, đảm bảo model tập trung vào thông tin phù hợp để trả lời.
Trong benchmark MMLU, 5-shot có thể là các đoạn liên quan đến quá trình quang hợp trước khi hỏi về chủ đề này.
Trong benchmark MMLU, 5-shot có thể là các đoạn thông tin thực tế về quang hợp trước khi hỏi về quá trình. Nhờ nắm được thông tin từ các shot, LLM có thể loại trừ các đáp án không phù hợp và xác định lựa chọn đúng.
7.4 Ví dụ:
Câu hỏi: Phát biểu nào dưới đây mô tả đúng nhất về quá trình quang hợp?
5-shot in-context:
- Câu 1: Cây là sinh vật sống có thể tự tổng hợp thức ăn.
- Câu 2: Quang hợp là quá trình tự nhiên xảy ra ở thực vật xanh.
- Câu 3: Trong quá trình quang hợp, cây sử dụng ánh sáng, nước và carbon dioxide để tạo ra glucose (đường) làm năng lượng.
- Câu 4: Oxy được giải phóng như sản phẩm phụ của quang hợp.
- Câu 5: Quang hợp là quá trình thiết yếu cho sự sống trên Trái Đất vì nó cung cấp nguồn năng lượng chính cho hầu hết sinh vật.
Giải thích: 5-shot này cung cấp ngữ cảnh về quang hợp, gồm định nghĩa, vai trò của ánh sáng, nước, CO2, và các sản phẩm.
Nhờ đó, khi model được hỏi câu hỏi trắc nghiệm về chủ đề này, LLM có thể loại bỏ đáp án không đúng và xác định đáp án phù hợp nhất.
Tóm lại, “shot” trong “5-shot in-context” là các ví dụ ngữ cảnh cụ thể, còn prompt engineering là chỉ dẫn rộng hơn cho việc thực hiện nhiệm vụ của LLM.
8 Chain-of-thought prompt là gì?
Chain-of-thought (CoT) prompt là một kỹ thuật giúp khuyến khích các mô hình ngôn ngữ lớn (LLMs) trình bày quá trình suy luận của mình khi trả lời câu hỏi hoặc hoàn thành nhiệm vụ. Cách này hoạt động bằng cách cung cấp cho LLM một chuỗi các bước hoặc các prompt trung gian để hướng nó đến lời giải mong muốn.
Dưới đây là các khía cạnh chính của Chain-of-thought prompting:
Mục tiêu:
- Prompt truyền thống thường giúp LLM đưa ra đáp án đúng, nhưng quá trình suy luận bên trong lại không rõ ràng.
- CoT prompt giúp làm sáng tỏ quy trình suy nghĩ của LLM.
Cách hoạt động:
- Main Prompt: Người dùng bắt đầu bằng một câu hỏi hoặc nhiệm vụ cho LLM.
- Intermediate Prompts: Một chuỗi các prompt phụ được đưa ra, từng bước hướng dẫn LLM qua các bước cụ thể trong quá trình suy luận. Các prompt này có thể yêu cầu LLM xác định thông tin liên quan, cân nhắc các khả năng hoặc thực hiện phép tính.
- Final Answer: Sau khi đi qua chuỗi prompt, LLM sẽ đưa ra đáp án cuối cùng và có thể giải thích lý do dựa trên các bước đã đi.
Lợi ích của CoT Prompting:
- Tăng khả năng giải thích: Nhờ làm rõ các bước suy luận, CoT prompt giúp người dùng hiểu model nghĩ gì và đánh giá tính hợp lý của đáp án.
- Hỗ trợ debug và phân tích lỗi: Nếu đáp án sai, phân tích các bước suy nghĩ giúp xác định lỗi và cải thiện prompt cho lần sau.
- Hướng dẫn tư duy phức tạp: Đặc biệt hiệu quả với những nhiệm vụ nhiều bước hoặc đòi hỏi suy luận sâu.
8.1 Ví dụ:
Giả sử có prompt yêu cầu LLM tính diện tích hình chữ nhật có chiều dài 5 và chiều rộng 3.
Prompt truyền thống:
- Diện tích hình chữ nhật có chiều dài 5 và chiều rộng 3 là bao nhiêu?
CoT Prompt:
- Bước 1: Công thức tính diện tích hình chữ nhật là gì?
- Bước 2: Chiều dài và chiều rộng cụ thể trong trường hợp này là bao nhiêu?
- Bước 3: Áp dụng công thức ở bước 1 với giá trị từ bước 2.
- Đáp án cuối cùng: Diện tích hình chữ nhật là 15 đơn vị vuông. (Giải thích các bước dẫn đến đáp án này).
Chain-of-thought prompting là một kỹ thuật hữu ích để tăng tính minh bạch và khả năng hiểu của các mô hình ngôn ngữ lớn.
9 Temperature
Trong bối cảnh các mô hình AI, đặc biệt là các mô hình sinh văn bản, temperature là một siêu tham số điều chỉnh mức độ ngẫu nhiên hoặc sáng tạo của output được sinh ra.
Temperature trong các mô hình AI thường nằm trong khoảng từ 0 đến 2, và thường được đặt ở mức 0.1 đến 0.2 để kiểm tra độ mạch lạc trong các mô hình NLP.
Temperature như một chiếc núm vặn giúp cân bằng giữa:
- Output xác định: Khi temperature thấp, model ưu tiên chọn các kết quả có xác suất cao nhất dựa trên dữ liệu và xác suất nội bộ. Điều này cho ra kết quả an toàn, dễ đoán nhưng ít sáng tạo.
- Khám phá sáng tạo: Khi temperature cao, model thử nhiều lựa chọn hơn kể cả ít xác suất hơn. Điều này giúp output sáng tạo hơn, bất ngờ hơn nhưng cũng dễ trở nên vô nghĩa hoặc không liên quan.
Cách temperature hoạt động:
- Phân phối xác suất: Mô hình sinh (như LLM) nội bộ dự đoán xác suất của từng từ (hoặc phần tử) tiếp theo khi xử lý prompt hoặc viết tiếp một câu.
- Sampling từ phân phối: Model sẽ lấy mẫu (chọn) một từ hoặc phần tử từ phân phối xác suất này để sinh tiếp output.
- Temperature là yếu tố điều chỉnh: Temperature điều chỉnh các xác suất này trước khi sampling. Cụ thể:
- Temperature thấp: Xác suất không bị thay đổi nhiều. Model sẽ chọn từ có xác suất cao nhất, output rất dễ dự đoán.
- Temperature cao: Xác suất được dàn trải hơn. Model dễ chọn các từ ít khả năng hơn, tạo ra output đa dạng, đôi khi kỳ lạ.
9.1 Chọn temperature như thế nào?
Tùy vào ứng dụng mà điều chỉnh cho phù hợp:
- Tác vụ yêu cầu độ chính xác cao: Cần độ ổn định, factual, viết code… => để temperature thấp, output nhất quán.
- Tác vụ sáng tạo: Viết truyện, thơ, ý tưởng… => tăng temperature để sinh ra nhiều phương án độc đáo hơn.
10 AI Model Benchmarks
10.1 GSM8k
GSM8k là viết tắt của Grade School Math 8k. Đây là bộ dữ liệu được thiết kế đặc biệt để đánh giá khả năng của các mô hình ngôn ngữ lớn (LLM) trong việc thực hiện các tác vụ toán học nhiều bước ở trình độ tiểu học.
Đánh giá LLM: GSM8k là benchmark giá trị để đo tiến bộ của các LLM trong các bài toán toán học nhiều bước. Nó cho phép các nhà nghiên cứu so sánh hiệu năng giữa các model khác nhau và nhận biết các điểm cần cải thiện.
10.2 MMLU: Multidisciplinary multiple choice questions
Cụm “MMLU: Multidisciplinary multiple choice questions, provided 5-shot in-context” chỉ phương pháp benchmark hoặc đánh giá dùng cho các LLM như tôi.
Giải thích từng thành phần:
- MMLU: Viết tắt của Multidisciplinary Multiple Choice Language Understanding. Tức là đánh giá khả năng hiểu và trả lời các câu hỏi trắc nghiệm đa ngành của LLM.
- Multidisciplinary: Các câu hỏi bao phủ nhiều lĩnh vực, không chỉ một chủ đề. Điều này kiểm tra kiến thức tổng quát của LLM cũng như khả năng vận dụng hiểu biết sang các lĩnh vực khác nhau.
- Multiple Choice: Các câu hỏi dạng lựa chọn đáp án. Định dạng này giúp chuẩn hóa việc đánh giá, tránh mơ hồ trong đáp án.
11 Autoregressive LLM
Một autoregressive LLM (Large Language Model) là một loại mô hình AI tạo ra văn bản từng từ (hoặc từng token) một, dự đoán từ tiếp theo dựa trên chuỗi đã xử lý trước đó.
Autoregressive LLMs có thể sử dụng nhiều kiến trúc khác nhau, trong đó transformer là lựa chọn phổ biến nhờ khả năng xử lý context hiệu quả, nhưng không chỉ giới hạn ở transformer.
- Autoregressive: Nghĩa là model “tham chiếu chính mình”, dựa vào văn bản đã sinh ra để quyết định bước tiếp theo. Tưởng tượng bạn đang viết truyện, cứ mỗi từ đều cân nhắc dựa trên các từ trước đó.
- Large Language Model (LLM): Tức là mô hình ngôn ngữ lớn, huấn luyện trên lượng dữ liệu văn bản khổng lồ. LLM có thể hiểu, phản hồi các prompt phức tạp, sinh văn bản đa dạng định dạng, dịch ngôn ngữ…
Cách hoạt động:
- Bắt đầu bằng prompt: Bạn đưa cho LLM một prompt hoặc câu hỏi mở đầu (vd: “Viết một bài thơ về con mèo”).
- Dự đoán từng từ: LLM phân tích prompt, dự đoán từ tiếp theo dựa trên kiến thức nội bộ và context.
- Tiếp tục dự đoán: Sau khi sinh ra từ đầu tiên, LLM lại dùng cả prompt và từ vừa sinh ra để đoán từ tiếp theo, cứ thế cho tới khi đạt độ dài yêu cầu hoặc gặp chỉ dẫn dừng.
- Sinh ra văn bản hoàn chỉnh: Lặp lại quá trình này cho tới khi kết thúc.
11.1 Lợi ích của Autoregressive LLMs:
- Rất mạch lạc: Do luôn xem xét context phía trước, output sinh ra thường đúng ngữ pháp, logic, mạch lạc.
- Đa dạng output: Nhờ vốn từ và dữ liệu lớn, model có thể sinh nhiều định dạng văn bản như thơ, code, script, văn bản formal/informal…
11.2 Hạn chế của Autoregressive LLMs:
- Truyền lỗi: Nếu dự đoán sai từ đầu, các từ sau có thể càng sai.
- Tốn tài nguyên: Vì phải xử lý tuần tự từng bước, model lớn cần tài nguyên tính toán rất lớn.
Autoregressive LLMs là công cụ mạnh để sinh ra văn bản tự nhiên như người, nhưng việc dựa vào dự đoán trước dễ gây lỗi dây chuyền và đòi hỏi nhiều tài nguyên.
Ngoài Autoregressive LLMs, còn nhiều loại LLM khác với các ưu/nhược điểm riêng:
12 Non-Autoregressive LLMs
- Không sinh văn bản tuần tự, mà xem xét toàn bộ prompt hoặc câu hỏi một lần rồi sinh ra output.
- Có thể nhanh, ít bị lỗi dây chuyền, nhưng khó giữ văn bản mạch lạc, cần huấn luyện bổ sung để đảm bảo chất lượng.
13 Conditional LLMs
Tương tự autoregressive, nhưng bổ sung thêm thông tin (condition) ngoài chuỗi trước đó để dẫn hướng việc sinh văn bản, cho phép kiểm soát output nhiều hơn.
Condition có thể bao gồm:
- Phong cách cụ thể (formal, informal)
- Cảm xúc mong muốn
14 Masked Language Models (MLMs)
Không trực tiếp sinh ra văn bản, nhưng rất mạnh trong việc dự đoán các từ thiếu trong chuỗi.
MLM thường là thành phần của các kiến trúc LLM khác (cả autoregressive), giúp model hiểu cấu trúc, quan hệ ngôn ngữ.
15 Encoder-Decoder LLMs
Sử dụng hai bước để xử lý các tác vụ như dịch máy hoặc tóm tắt.
- Encoder: Phân tích input (vd: ngôn ngữ nguồn để dịch) và trích xuất ý nghĩa.
- Decoder: Sinh ra output (vd: ngôn ngữ đích) dựa trên thông tin từ encoder.
Transformer là kiến trúc phổ biến cho encoder-decoder.
Và như vậy!
Hãy nhớ, lĩnh vực AI luôn phát triển không ngừng và liên tục xuất hiện các mô hình mới. Hãy luôn tò mò và khám phá!
Hy vọng bạn thấy thú vị và học thêm được điều mới hôm nay!