Understanding LLM Basics: Parameters, Tokens, Context

title : Understanding LLM Basics: Parameters, Tokens, Context
Understanding Parameters (Size Complexity), Context Size, Tokens, Temperature, Shots, Chain of thought (CoT) prompts, and Benchmarks (GSM8k, MMLU) in the context of AI Models
What do terms like temperature, shots, parameters eg. 7B, 13B, 70B, and Benchmarks (GSM8K, MMLU), CoT, Autoregressive LLMs etc. actually mean in the context of AI Models?
1 Introduction
Grok 1 the open source LLM model by xAI was recently made open source in March 2024. The xAI website contained the following description for Grok 1.
Grok-1 is a 314 billion parameter Mixture-of-Experts model trained from scratch by xAI.
After announcing xAI, we trained a prototype LLM (Grok-0) with 33 billion parameters. This early model approaches LLaMA 2 (70B) capabilities on standard LM benchmarks but uses only half of its training resources
Grok 1 is an autoregressive LLM was recently released and boasted the following performance benchmarks using 30B evaluated at a temperature of 0.1 with a context window of 1092 tokens.
The initial Grok-1 has a context length of 8,192 tokens and is released in Nov 2023.
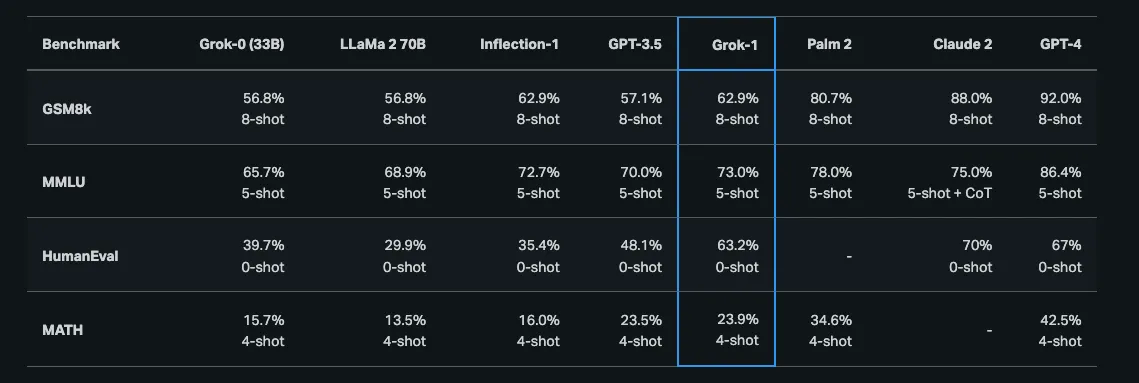
Additionally while reading about AI models you will frequently come across something like this,
Following are the quick stats for the Llama 2, the AI Model from Meta AI.
Params: 7B to 70B parameters (7B, 13B, 70B) Context size: 4048 Trained on: 2 trillion tokens Github: Source Code Try it: HuggingFace
So what do terms like temperature, shots, parameters eg. 7B, 13B, 70B, and Benchmarks (GSM8K, MMLU), CoT, Autoregressive LLMs etc. actually mean?
2 Parameters (70B vs 7B parameters) — Size and Complexity of the AI Model)
70B this indicates that the specific model has 70 billion parameters. It is a measure of the size and complexity of the AI model. Generally the larger the parameters the more complex and powerful the AI model.
Grok-1 is a 314 billion parameter, a bigger and more complex AI model.
In the context of machine learning models, especially neural networks, parameters are numerical values that the model learns and adjusts during training.
A higher number of parameters generally allows a model to represent more complex relationships within the data and potentially achieve better performance on tasks.
AI Models come in varying sizes and complexity. However, it’s important to note that the number of parameters is not the only factor that determines the effectiveness of an LLM. Other factors like the model architecture, training data, and training techniques also play a significant role.
Also note that the 70B refers to the number of parameters in the model, not the size of the training data.
For example, the 70B LLM model may be trained in petabytes of data.
Note also that both parameters and training data size are crucial factors in the performance of large language models.
However bigger is not always preferred and the trend is have AI models that are smaller in parameter size eg. 7B, and using a lesser number of training resources.
For example Llama 2 release introduces a family of pretrained and fine-tuned LLMs, ranging in scale from 7B to 70B parameters (7B, 13B, 70B).
Larger AI models require more computational power to run and are typically run on large proprietary servers.
Consequently AI models with smaller parameters that can provide the same output of the larger parameter models may be preferred if we want to run the AI models on laptops or smart phones.
This can be achieved by a process called AI Model distillation where a smaller simpler model can mimic the decisions of a larger complex model.
3 AI Model distillation
Model distillation is a machine learning process that teaches a smaller, simpler “student” model to mimic a bigger complex “teacher” model.
By learning from the teacher outputs, the student model can make similar decisions without needing a bigger more complex model. Such student AI models can be smaller in size and faster and cheaper computationally and could potentially be run on phones and laptops.
Eg. (SQLCoder 7B vs SQLCoder70B) an open source AI model that some say out performs GPT 4, built by Defog on the codeLlama-70B.
3.1 The Distillation Process:
- Pre-trained Teacher Model: The process starts with a large, pre-trained model that has already been trained on a massive dataset and performs well on a specific task (e.g., image classification, language translation).
- Knowledge Transfer: During distillation, the teacher model acts as a guide, indirectly transferring its knowledge to the student model.
- Student Model Training: The student model is trained on two sources of information:
- The original training data used for the teacher model.
- The predictions (outputs) made by the teacher model on the same data. This essentially teaches the student model how to mimic the behavior of the teacher model.
4. Compact and Efficient Student: Through this training process, the student model learns to perform similarly to the teacher model, but with a significantly smaller size and lower computational requirements.
4 HuggingFace and OpenSource AI
AI models can be propreitary (closed source) eg. ChatGPT (OpenSource AI), Gemini (Google AI), Claude (Anthropic AI), etc. or OpenSource source eg. Llama 2 (Meta AI), Grok 1 (x AI)etc.
Open source AI Models allow you to peruse the base AI Model models and build upon them.
There are several Open Source AI models available on HuggingFace (the Github of AI Models). https://huggingface.co/models
As of March 2024 HuggingFace has over 500K open source AI Models.
If the AI model is open Source then users can deploy, run and further build upon them.
Smaller open source AI models can be deployed on powerful laptops, and larger AI models can be run in the cloud. Google Vertex AI is google’s cloud based platform to run AI models.
5 Build, Run and Deploy your own AI Models
Google Vertex AI provides a cloud based platform where you can deploy and run AI Models from HuggingFace.
Vertex AI is a machine learning (ML) platform that lets you train and deploy ML models and AI applications, and customize large language models (LLMs) for use in your AI-powered applications. Vertex AI provides a unified platform that seamlessly integrates data preparation, model training, deployment, and monitoring. This significantly reduces the complexity of managing different components and services separately.
References:
- https://huggingface.co/blog/gcp-partnership
- Deploying 🤗 Hub models in Vertex AI https://huggingface.co/blog/alvarobartt/deploy-from-hub-to-vertex-ai
- Vertex AI pricing https://cloud.google.com/vertex-ai/generative-ai/pricing
6 Tokens
Tokens are a representation of words in an AI model and form the fundamental units of information used to represent text data.
In NLP LLMs words are fed to the AI Model in the form of tokens. Words are converted into tokens, using a particular tokenization method.
The process of converting text data into tokens is called tokenization. This involves breaking down the text into its constituent units based on the chosen tokenization method.
The choice of tokenization method and the size and diversity of the training data (measured in tokens) significantly impact the capabilities of LLMs.
Example
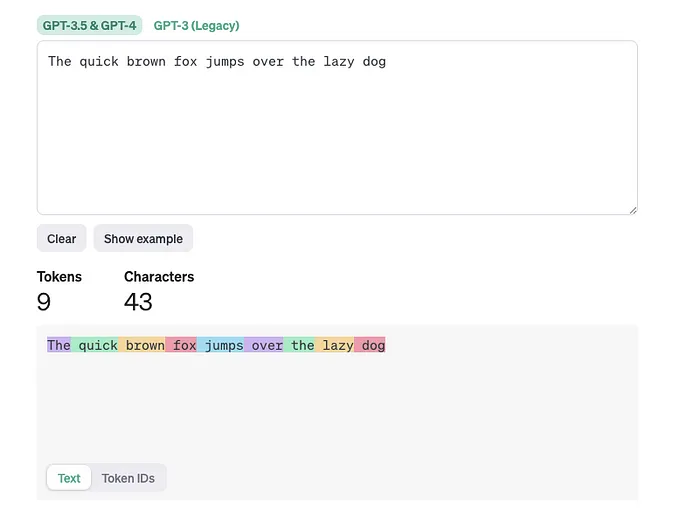
Text Tokens
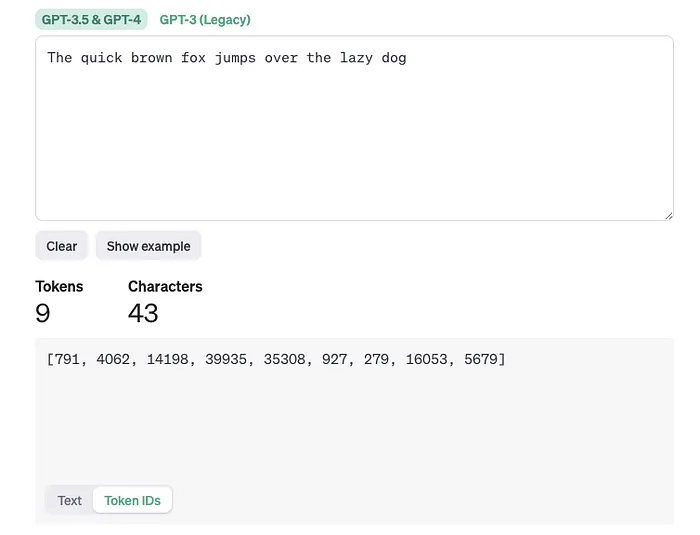
Token Ids
Ref: https://platform.openai.com/tokenizer
LLMs or Large Language Models as the name suggests are AI models that are trained on a large text datasets.
So for example an LLM that was trained on a dataset consisting of 2 trillion tokens, is trained on a huge amount of text data, and it’s what allows the LLM to develop its understanding of language.
In general, the more tokens an LLM is trained on, the greater its exposure to different words, phrases, and how language is used in various contexts. This can lead to improvements in:
- Vocabulary: The LLM encounters a wider range of words and learns their meanings.
- Grammar and Syntax: It learns the rules of grammar and how to structure sentences correctly.
- Nuances and Context: The LLM becomes better at understanding the subtleties of language and how meaning can change depending on the context.
6.1 Why Use Tokens?
Representing words as tokens allows AI models to mathematically process data thus allowing the use of different AI architectures to establish mathematical mapping between different words and relations between the data thereby allowing the AI to generate “context” to the data.
Note that since tokens are a fundamental building block and unit of input to the AI Models, several AI Models use tokens as a unit to measure the usage of the data model eg. input and output, and use that for pricing the use of the data model.
Ref: https://openai.com/pricing

GPT 4 Turbo Pricing Model (based on Tokens used)
You can think of tokens as pieces of words used for natural language processing. For English text, 1 token is approximately 4 characters or 0.75 words. As a point of reference, the collected works of Shakespeare are about 900,000 words or 1.2M tokens.
7 Context Length vs. Context Window
7.1 Context length
Context length is the maximum number of tokens that the AI model can process at once.
For example for ChatGPT 3.5 it is 4096 tokens. This means that ChatGPT 3.5 cannot take inputs of longer than 4096 tokens (it will truncate the input). This also means that GPT 3.5 cannot generate output longer than 4096 tokens in one go, it will instead generate it in batches of 4096.
As an example I asked GPT 3.5 to list out all the numbers from 1 to 1000, that would exceed its context length of 4096. GPT 3.5 stopped at once it reached this limit and them prompted me to “continue” and generated the next set of numbers in a separate batch.
NOTE the initial Grok-1 has a context length of 8,192 tokens and is released in Nov 2023.
Also note that many-a-times the context length is denoted in the name of the AI model eg. “XGen-7B-4K-base” (Salesforce AI), The “4K” in “XGen-7B-4K-base” likely denotes the model’s context length or maximum number of tokens it can process at once, which is 4096 tokens. This means the model can consider up to 4096 tokens of text when generating a response.
Note also the 7B indicates the size/complexity of the AI model, however despite its relatively small size of 7 billion parameters, XGen punches well above its weight, delivering performance that rivals or exceeds that of much larger AI models.
7.2 Context Window
Context window refers to the number of tokens that the AI model considers when generating a response. It typically includes the most recent tokens in the conversation, allowing to provide relevant and coherent responses based on the context of the conversation.
The context window allows the AI model to remember what you have said about that topic in previous prompts. This helps the model generate more coherent and consistent responses.
The context window in language models like GPT refers to the amount of text the model can consider when generating responses.
It’s the model’s working memory, determining how much previous text it can recall in the specific chat, crucial for maintaining coherent and contextually relevant dialogue or text generation.
GPT 3.5’s context length is 4096 tokens, which means it can process up to 4096 tokens at once.
GPT 3.5’s context window, on the other hand, is 2048 tokens, which means that it considers only the last 2048 tokens of the conversation when generating a response.
GPT-4 Turbo has a context window of 128k tokens which is the equivalent of more than 300 pages of text. This allows the model to generate more contextually relevant and nuanced responses.
7.3 What is “5-shot in-context”?
“Shot” (like “5-shot in-context”) gives a small set of relevant examples (the “shots”) to large language models before a task. This helps them understand the context and reasoning behind the task, leading to better performance on specific questions that require nuance. It’s like giving background information to an LLM to help it solve a problem.
5-shot in-context: This is a crucial aspect of the evaluation process of an AI Model. It refers to the following:
- 5-shot: Before answering the question, the LLM is provided with 5 relevant examples or snippets of text (the “shot”) that provide context for the question. This allows the model to better understand the topic and reasoning behind the question.
- In-context: The 5 examples are directly related to the specific question being asked. This ensures the model is focusing on the relevant information for answering the question.
In the MMLU benchmark, the 5-shot might be snippets of text related to photosynthesis before a question about the process.
In an MMLU benchmark, the 5-shot might be factual snippets about photosynthesis before a question on the process. By understanding the information in the shots, the LLM can distinguish between options like “uses sunlight for energy” and “requires large amounts of water.”
7.4 Example:
Question: Which of the following statements best describes the process of photosynthesis?
5-shot in-context:
- Sentence 1: Plants are living organisms that can produce their own food.
- Sentence 2: Photosynthesis is a natural process that occurs in green plants.
- Sentence 3: During photosynthesis, plants use sunlight, water, and carbon dioxide to create glucose (sugar) for energy.
- Sentence 4: Oxygen is released as a byproduct of photosynthesis.
- Sentence 5: Photosynthesis is essential for life on Earth as it provides the primary source of energy for most living things.
Explanation: The 5-shot provides context related to photosynthesis, including its definition, the role of sunlight, water, and carbon dioxide, and the products of the process.
With this context, when the AI model is asked a question where it has to select from multiple choice answers, the LLM can eliminate irrelevant answer choices and identify the option that best describes photosynthesis.
In conclusion, “shot” in “5-shot in-context” refers to specific contextual examples, while prompt engineering encompasses a broader approach to guiding the LLM’s task execution.
8 What is Chain-of-thought prompt?
A chain-of-thought (CoT) prompt is a technique used to encourage large language models (LLMs) to explain their reasoning process when answering a question or completing a task. It works by providing the LLM with a series of steps or intermediate prompts that guide it towards the desired solution.
Here’s a breakdown of the key aspects of CoT prompting:
Motivation:
- Traditional LLM prompts often result in accurate answers, but the internal reasoning process behind those answers remains unclear.
- CoT prompting aims to address this by making the LLM’s thought process more transparent.
How it Works:
- Main Prompt: The user starts with a question or task prompt for the LLM.
- Intermediate Prompts: A series of additional prompts are provided, each guiding the LLM through a specific step in the reasoning process. These prompts might ask the LLM to identify relevant information, consider different possibilities, or perform calculations.
- Final Answer: After following the chain of prompts, the LLM arrives at the final answer and potentially explains its reasoning based on the steps it took.
Benefits of CoT Prompting:
- Improved Interpretability: By revealing the reasoning steps, CoT prompts allow users to understand how the LLM arrived at the answer and assess its validity.
- Debugging and Error Analysis: If the answer is incorrect, analyzing the reasoning steps can help identify where the LLM went wrong and improve future prompts.
- Guiding Complex Reasoning: CoT prompts can be particularly helpful for tasks that require multi-step reasoning or navigating complex information.
8.1 Example:
Consider a prompt asking the LLM to calculate the area of a rectangle with a length of 5 units and a width of 3 units.
Traditional Prompt:
- What is the area of a rectangle with a length of 5 units and a width of 3 units?
CoT Prompt:
- Step 1: What is the formula for calculating the area of a rectangle?
- Step 2: What are the length and width of the rectangle in this case?
- Step 3: Apply the formula from step 1 with the values from step 2.
- Final Answer: The area of the rectangle is 15 square units. (Explain the steps used to reach this answer).
Chain-of-thought prompting is a valuable technique for enhancing the transparency and understandability of large language models.
9 Temperature
In the context of AI models, particularly generative models, temperature refers to a hyper parameter that controls the randomness or creativity of the generated outputs.
Temperature settings in AI models typically range from 0 to 2 with it being typically set to 0.1 to 0.2 to test coherence in NLP models.
It acts like a dial that fine-tunes the balance between:
- Deterministic Outputs: When the temperature is low, the model prioritizes the most likely outputs based on its training data and internal probabilities. This leads to more predictable and safe outputs, but they might also be less creative or interesting.
- Creative Exploration: When the temperature is high, the model explores a wider range of possibilities, even if they are less probable. This can lead to more creative and surprising outputs, but also to outputs that are grammatically incorrect, nonsensical, or irrelevant to the prompt.
Here’s a breakdown of how temperature works:
- Probability Distribution: Generative models like large language models (LLMs) internally predict the probability of each possible next word or element in a sequence when processing a prompt or continuing a sentence.
- Sampling from the Distribution: The model then samples (chooses) a word or element from this probability distribution to generate the next output.
- Temperature as a Modifier: Temperature acts as a modifier on these probabilities before sampling. Here’s how it affects the sampling process:
- Low Temperature: If the temperature is low, the probabilities are only slightly modified. The model is more likely to choose the word with the highest probability, resulting in predictable outputs.
- High Temperature: If the temperature is high, the probabilities are spread out more. This increases the chance of the model choosing less likely words, leading to more creative but potentially nonsensical outputs.
9.1 Finding the Right Temperature
The ideal temperature setting depends on the specific application and desired outcome. Here are some examples:
- High Accuracy Tasks: For tasks requiring high accuracy, like generating factual summaries or writing code, a low temperature is preferred to ensure reliable and consistent outputs.
- Creative Text Generation: For tasks emphasizing creativity, like writing poems or generating story ideas, a higher temperature can be used to explore a wider range of possibilities and spark innovative ideas.
10 AI Model Benchmarks
10.1 GSM8k
GSM8k stands for Grade School Math 8k. It’s a dataset specifically designed to evaluate the ability of large language models (LLMs) to perform multi-step mathematical reasoning tasks.
Benchmarking LLMs: GSM8k serves as a valuable benchmark for evaluating the progress of LLMs in handling multi-step mathematical reasoning. It allows researchers to compare the performance of different models and identify areas for improvement.
10.2 MMLU: Multidisciplinary multiple choice questions
The phrase “MMLU: Multidisciplinary multiple choice questions, provided 5-shot in-context” refers to a specific type of benchmark or evaluation method used for large language models (LLMs) like me.
Here’s a breakdown of its components:
- MMLU: This stands for Multidisciplinary Multiple Choice Language Understanding. It indicates that the evaluation focuses on the LLM’s ability to understand and answer multiple-choice questions across various disciplines or domains.
- Multidisciplinary: The questions cover a wide range of topics, not limited to a single field. This assesses the LLM’s general knowledge and ability to apply its understanding to different areas.
- Multiple Choice: The format of the questions involves choosing the correct answer from a set of pre-defined options. This allows for standardized evaluation and avoids ambiguity in responses.
11 Autoregressive LLM
An autoregressive LLM (Large Language Model) is a type of AI model that generates text one word (or token) at a time, predicting the most likely next word based on the sequence it has already processed.
Autoregressive LLMs can utilize various architectures, with transformers being a popular choice due to their effectiveness in understanding context. However, autoregressive models are not limited to transformers.
- Autoregressive: This means the model is “self-referential,” relying on its own previously generated text to determine what comes next. Imagine writing a story one word at a time, using the previous words to guide your next choice.
- Large Language Model (LLM): This refers to a powerful AI model trained on massive amounts of text data. LLMs can understand and respond to complex prompts and questions, generate different creative text formats, and translate languages.
How it Works:
- Start with a Prompt: You provide the LLM with a starting prompt or question (e.g., “Write a poem about a cat”).
- Word-by-Word Prediction: The LLM analyzes the prompt and predicts the most likely word to follow based on its internal knowledge and the context of the prompt.
- Continued Prediction: Once it generates the first word, the LLM uses that word along with the original prompt to predict the next most likely word, and so on.
- Full Text Generation: This process continues until the LLM reaches a stopping point based on the length requirement or a specific ending instruction.
11.1 Benefits of Autoregressive LLMs:
- High Coherence: By considering the preceding text, autoregressive models can generate outputs that are more grammatically correct and follow a logical flow of ideas.
- Diverse Outputs: With a vast vocabulary and knowledge base, these models can generate creative text formats like poems, code, scripts, or different writing styles (formal, informal).
11.2 Drawbacks of Autoregressive LLMs:
- Error Propagation: If the model makes an early mistake in its prediction, it can lead to subsequent errors as the generation continues.
- Computationally Expensive: The need to analyze and predict each word sequentially can be computationally demanding for large models.
Autoregressive LLMs are a powerful tool for generating human-quality text, but their reliance on previous predictions can lead to errors and require significant computational resources.
Beyond Autoregressive LLMs, there are several other types of large language models (LLMs) with different strengths and approaches to processing information and generating text.
Here’s a glimpse into some prominent categories:
12 Non-Autoregressive LLMs
- Unlike autoregressive models that generate text sequentially, non-autoregressive models consider the entire prompt or question at once before generating the output.
- This can potentially be faster and more efficient than autoregressive models and might be less prone to error propagation issues that can occur in autoregressive generation.
- However maintaining coherence and logical flow in the generated text may be challenging, and may require additional training strategies to ensure high-quality outputs.
13 Conditional LLMs
Similar to autoregressive models, they generate text one step at a time. However, they incorporate additional information (conditions) beyond the previous sequence to guide the generation process, and may offer more control over the generated text compared to traditional autoregressive models.
Conditions can include:
- Specific styles (e.g., formal, informal)
- Desired emotional tone
14 Masked Language Models (MLMs)
These models don’t directly generate text but excel at predicting missing words within a sequence.
MLMs are often used as building blocks for other LLM architectures, including some autoregressive models. They contribute to the model’s understanding of language structure and relationships between words.
15 Encoder-Decoder LLMs
These models utilize a two-stage process for tasks like machine translation or text summarization.
- Encoder: Analyzes the input text (source language for translation) and captures its meaning.
- Decoder: Generates the output text (target language for translation) based on the encoded representation from the first stage.
Transformers are a common architectural choice for encoder-decoder models.
And that’s it!
Remember, the field of AI is constantly evolving, and new models are emerging all the time. Stay curious and keep exploring!
Hope you found this interesting and learnt something new today!